LLM Benchmarks
Understand LLM benchmarks, AI model evaluations, reasoning tests, coding benchmarks, multimodal scores, and real-world model performance.
Benchmarks are signals, not truth
A high benchmark score can indicate capability, but it does not guarantee reliability in a specific product workflow.
Look for task match
Coding, math, reasoning, long context, tool use, and multimodal work need different evaluations. One leaderboard rarely answers every question.
Test with your own work
Teams should use benchmarks to shortlist models, then run their own prompts, documents, tests, and acceptance criteria.
Featured LLM Benchmarks Coverage
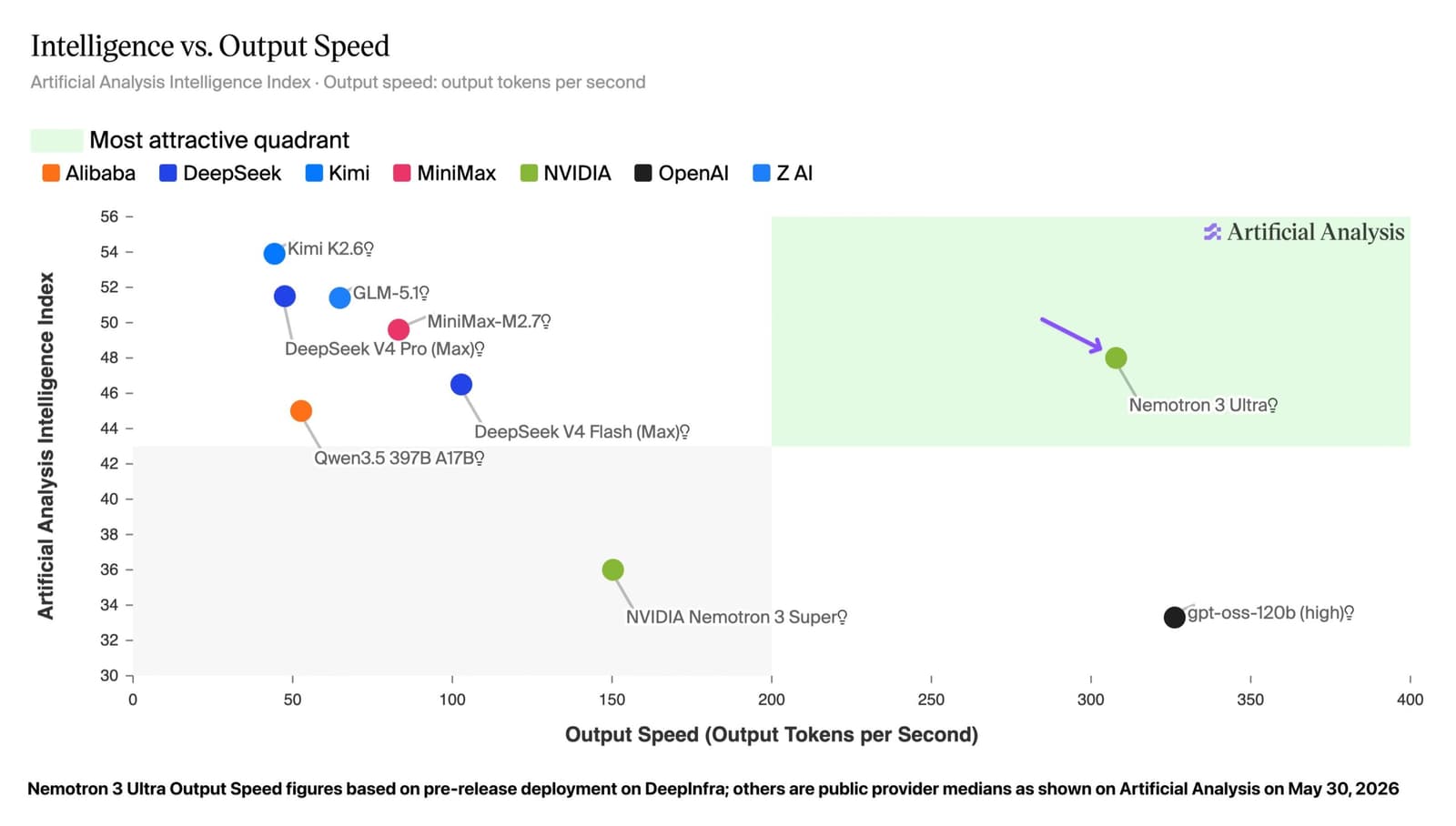
Nvidia Nemotron 3 Ultra: The Sharpest Open US Model – Still Behind China
Nemotron 3 Ultra tops US open‑source benchmarks but lags China’s offerings. Here’s a quick verdict on who should adopt it and why.
Latest LLM Benchmarks Articles

UK's AI Security Institute finds standard benchmarks systematically
UK's AI Security Institute study reveals standard benchmarks underestimate AI agent capabilities.

The agent evaluation gap: Enterprise AI organizations have a
Enterprise AI organizations face a reality-alignment problem, not a coverage problem, when evaluating AI agents.
Related AI Topics
Related AI Searches
Open Source AI Models
Follow open source AI models, open-weight LLMs, local AI, benchmarks, privacy, hardware requirements, and deployment workflows.
ChatGPT vs Claude
Compare ChatGPT and Claude by workflow: writing, coding, research, long documents, reasoning, files, business controls, privacy, and everyday productivity.
ChatGPT vs Claude Coding
Compare ChatGPT and Claude for coding workflows including debugging, refactoring, tests, architecture review, documentation, and pull request support.
Gemini vs ChatGPT
Compare Gemini and ChatGPT for search, writing, coding, multimodal work, productivity, research, and everyday AI assistance.
LLM Benchmarks FAQ
What are LLM benchmarks?
LLM benchmarks are tests used to compare language models on tasks such as reasoning, coding, math, knowledge, long context, and tool use.
Are AI benchmarks reliable?
They are useful but incomplete. Data contamination, prompt format, scoring design, and task mismatch can affect results.
How should teams use benchmarks?
Use benchmarks to narrow options, then test models on real tasks, costs, latency, and failure modes.